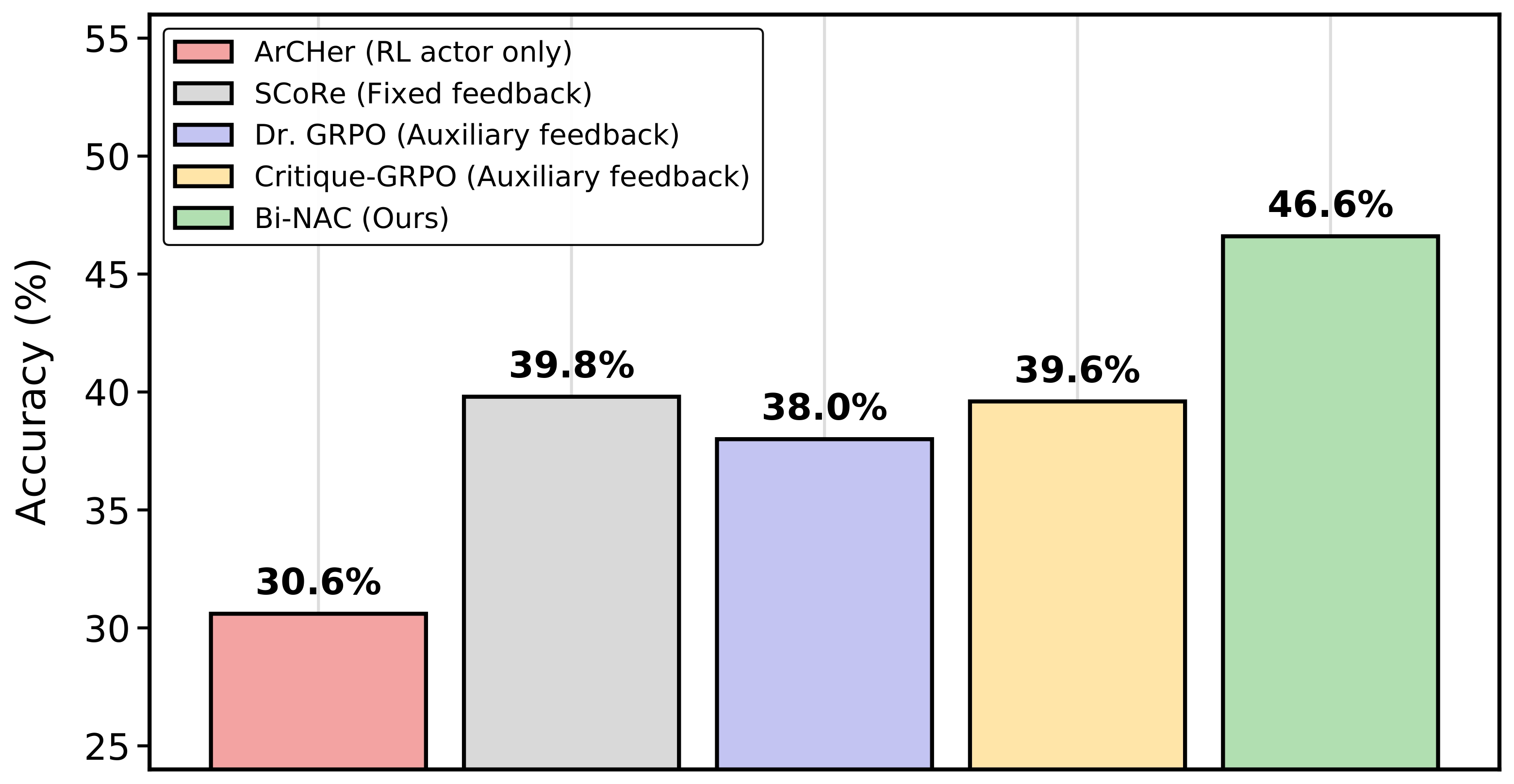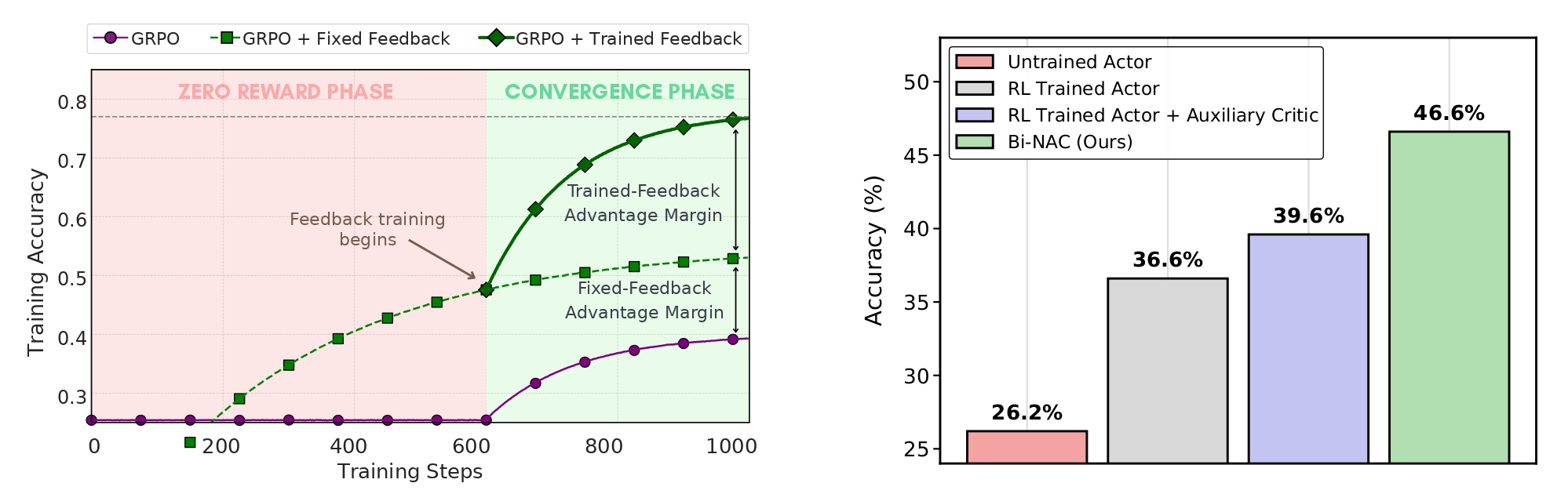
Abstract
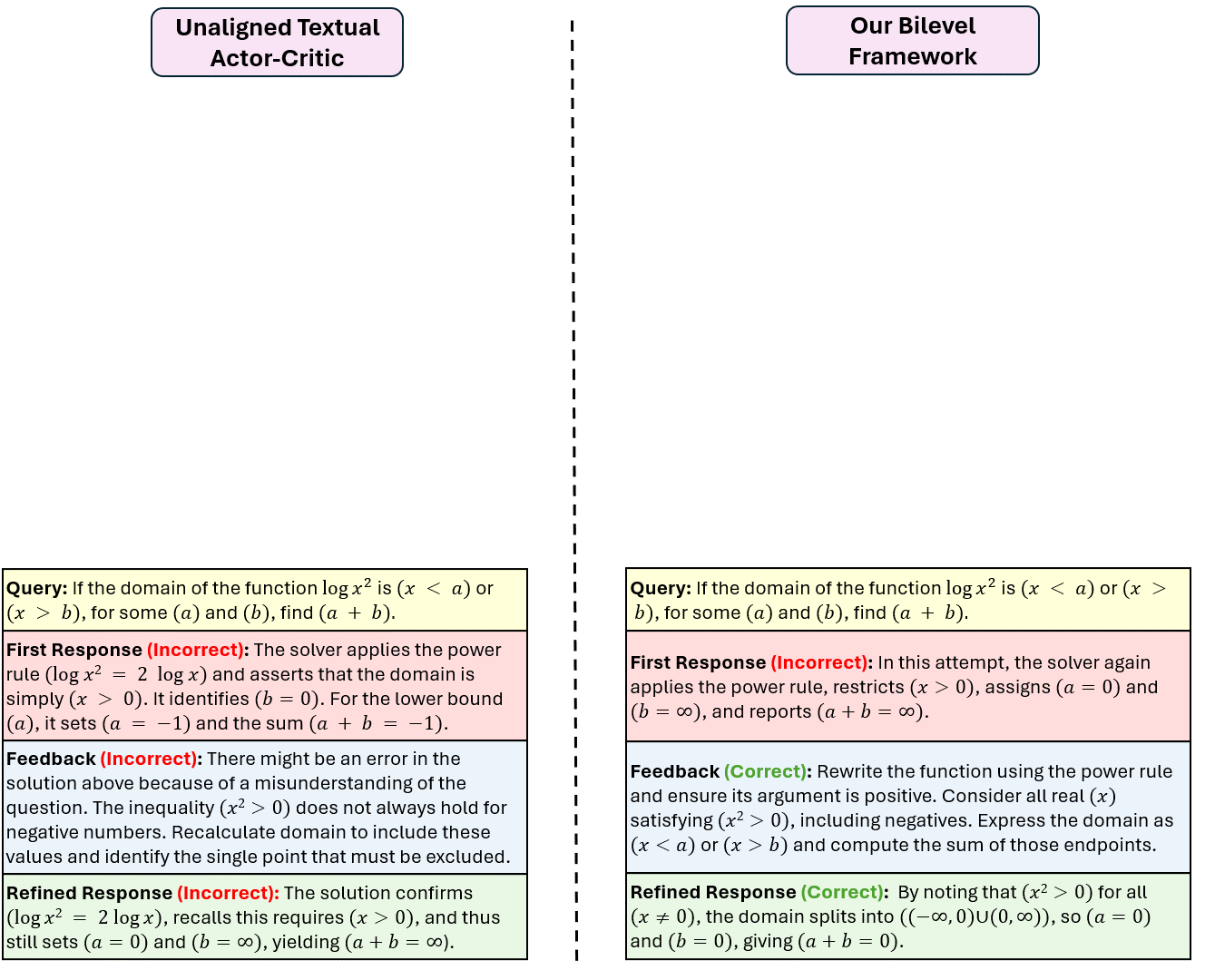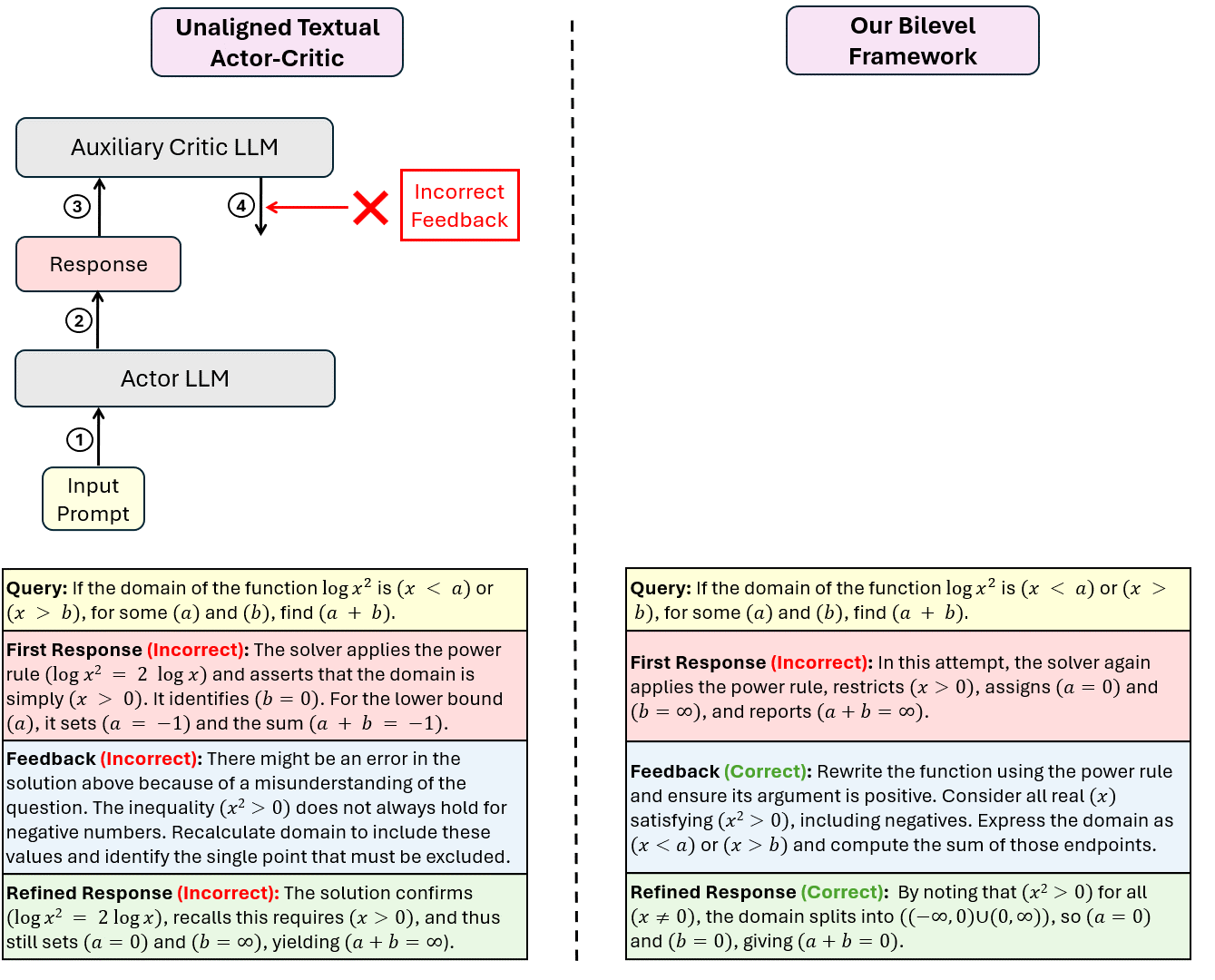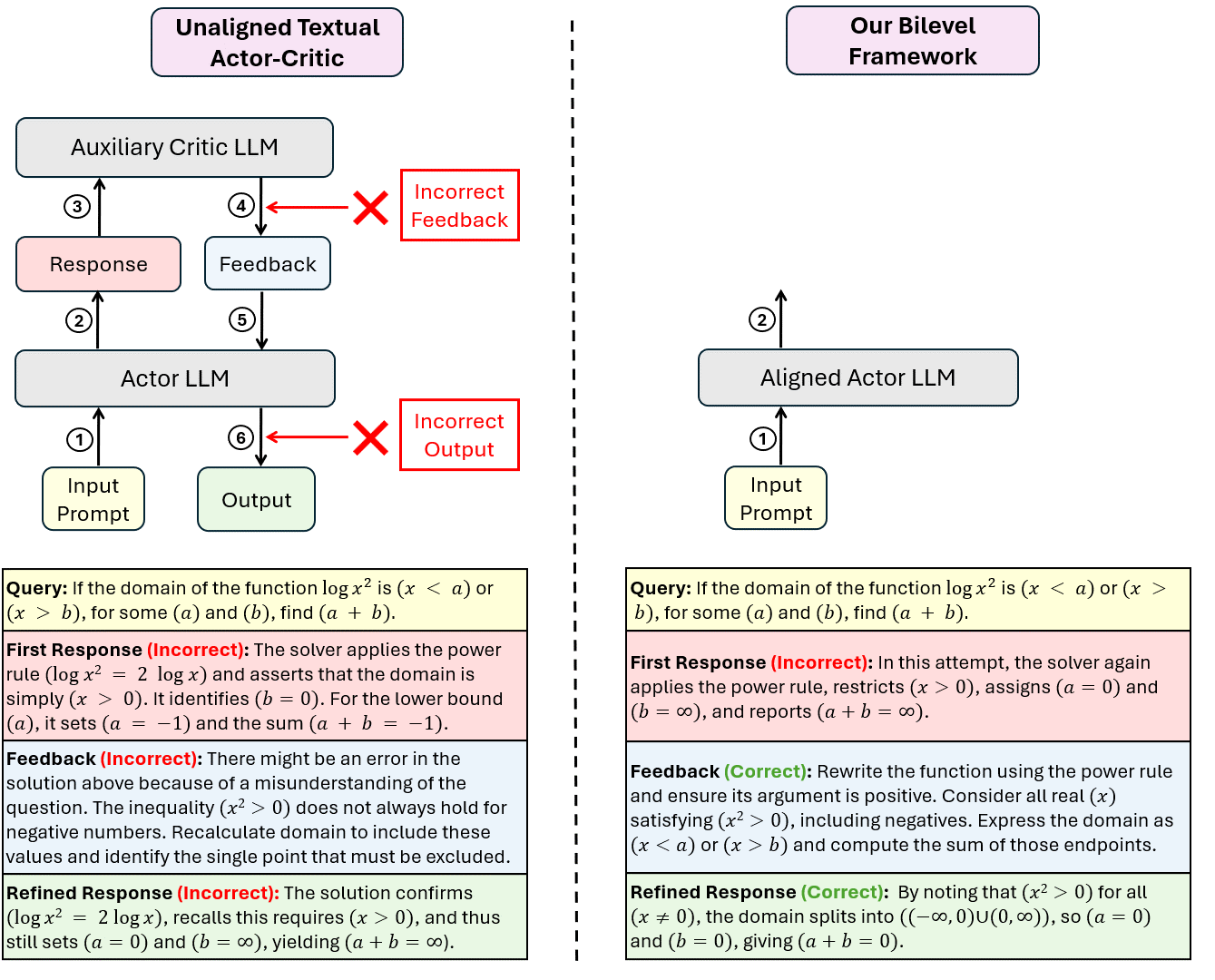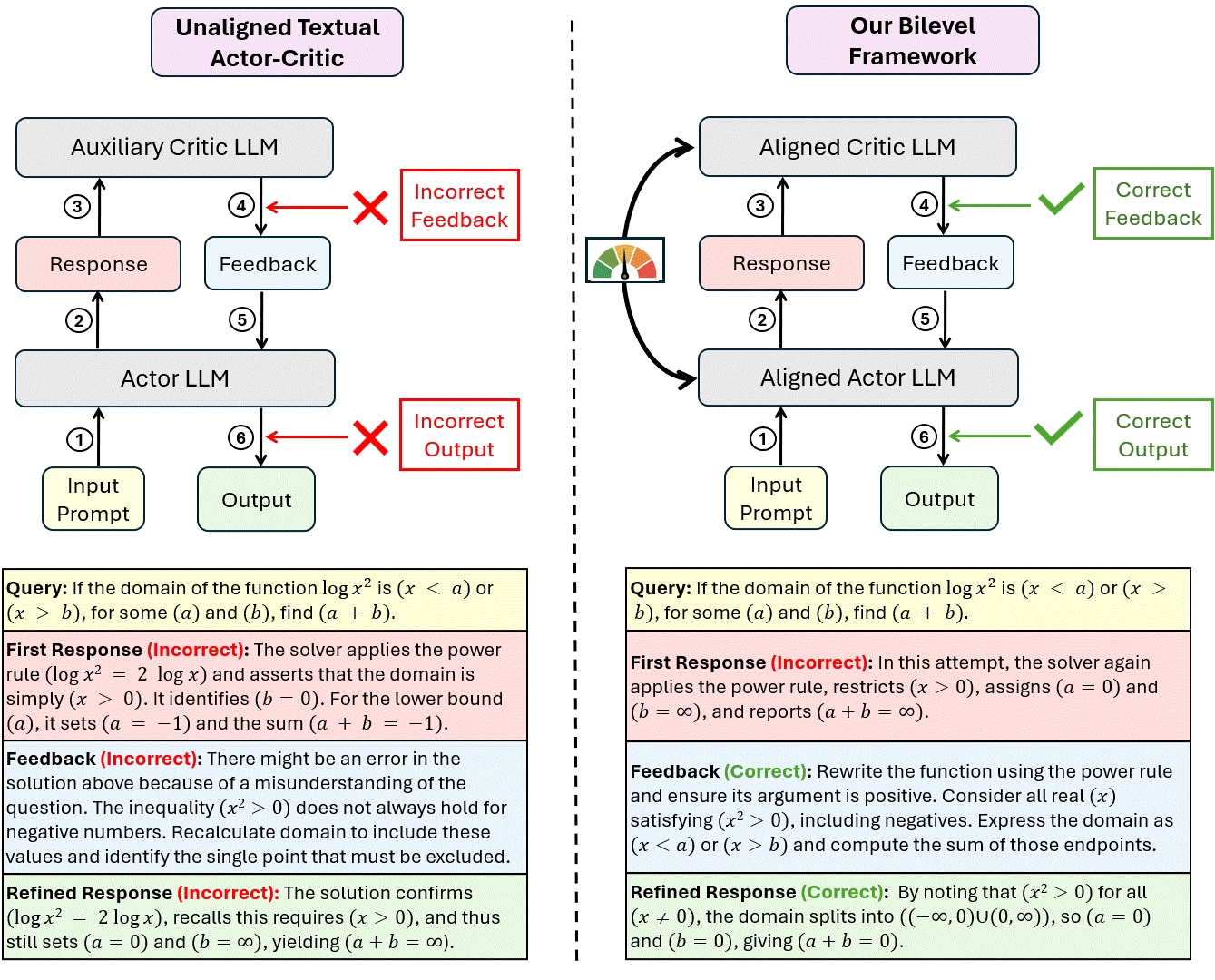
Reinforcement learning with verifiable rewards can improve LLM reasoning, but learning remains sample-inefficient when terminal rewards are sparse. This has motivated a growing line of work on RL with textual feedback, where a critic model generates natural language feedback to guide a reasoning model (the actor), augmenting scalar rewards with richer learning signals. However, existing methods typically treat feedback as fixed or auxiliary, which misses a key property: feedback should not merely be correct, but should improve the policy (actor model) when provided in context. This motivates a paradigm of learnable textual feedback for RL. Yet the learnability and usefulness of feedback depend on the policy's ability to learn from it, making RL with learnable feedback an inherently bilevel problem. We formalize this coupling as a Stackelberg bilevel program and derive Bilevel Natural Language Actor-Critic (Bi-NAC), which jointly trains a critic to generate reward-improving feedback and an actor to exploit it. Across MATH-500, MBPP, and GPQA, Bi-NAC improves sample and parameter efficiency over RL and fixed-critic baselines: our 2B model outperforms the 3B GRPO baseline, achieving 46.6% versus 41.4% on MATH-500, while our 6B model surpasses the 7B GRPO baseline, achieving 49.3% versus 43.6% on GPQA.